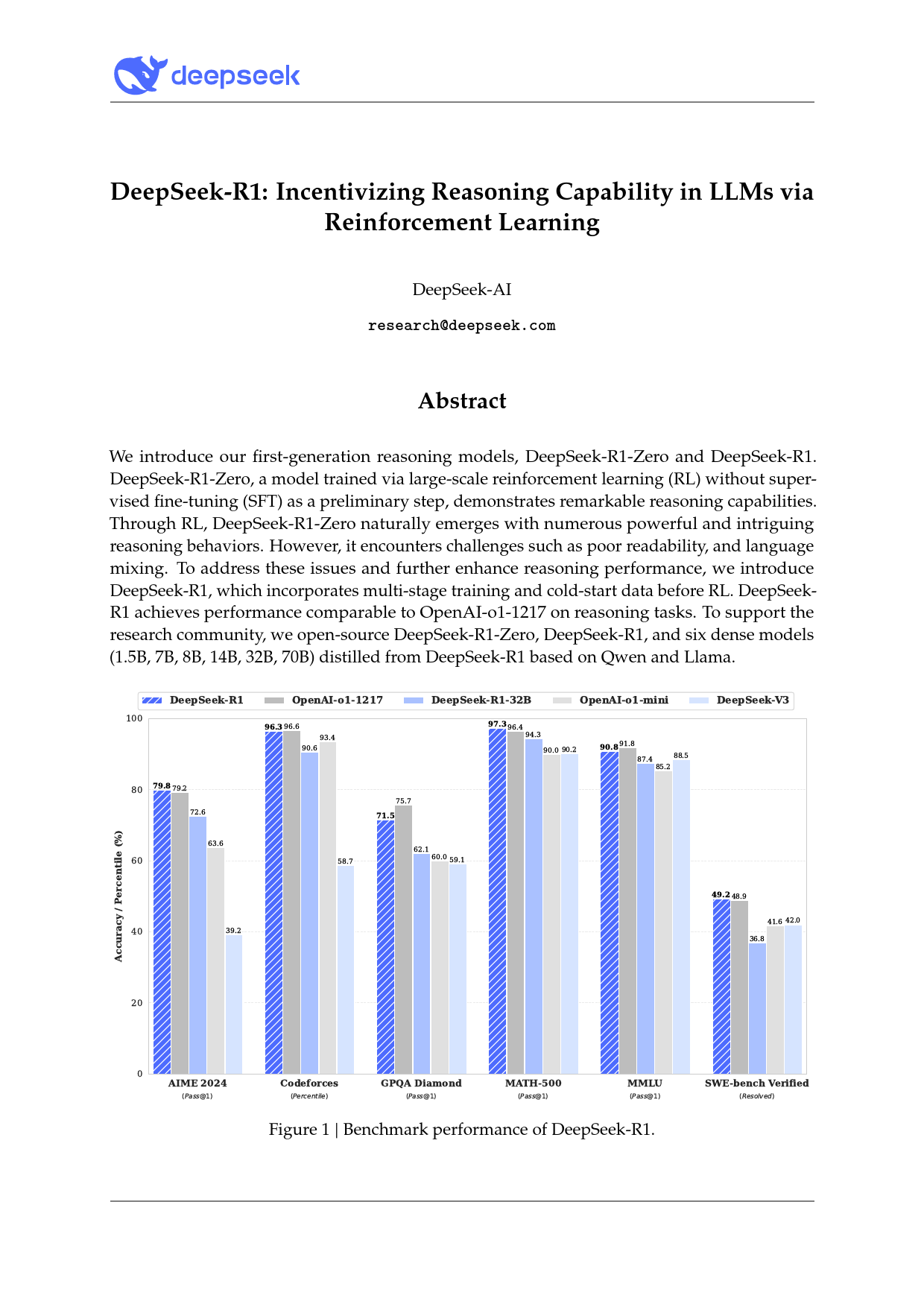
DeepSeek-R1:IncentivizingReasoningCapabilityinLLMsviaReinforcementLearningDeepSeek-AIresearch@deepseek.comAbstractWeintroduceourfirst-generationreasoningmodels,DeepSeek-R1-ZeroandDeepSeek-R1.DeepSeek-R1-Zero,amodeltrainedvialarge-scalereinforcementlearning(RL)withoutsuper-visedfine-tuning(SFT)asapreliminarystep,demonstratesremarkablereasoningcapabilities.ThroughRL,DeepSeek-R1-Zeronaturallyemergeswithnumerouspowerfulandintriguingreasoningbehaviors.However,itencounterschallengessuchaspoorreadability,andlanguagemixing.Toaddresstheseissuesandfurtherenhancereasoningperformance,weintroduceDeepSeek-R1,whichincorporatesmulti-stagetrainingandcold-startdatabeforeRL...






发表评论取消回复